Code Conversion: Language Model vs. Expert System


Over the past two years, we have witnessed a next revolution in the IT industry. Machine learning, neural networks, deep learning, artificial intelligence and finally Chat GPT and Copilot have captured the first lines of headlines in all mass media. Technology, which until recently was the domain of engineers and IT specialists is now available to everyone. The rapid development of artificial intelligence has undoubtedly influenced many areas of our lives, and the IT sphere is no exception. Adding AI into applications can enhance their capabilities and provide valuable functionalities. We decided to look at the capabilities of advanced technologies in programming language migration under a magnifying glass and answer the most important question - what is the place of language models in the complex automated database migration or application code conversion? Without further adieu, let’s start.
AI essentials: a Deep Dive
People often use deep learning and machine learning interchangeably, but it's helpful to understand the differences. All three - machine learning, deep learning, and neural networks - are part of artificial intelligence. However, neural networks is actually a sub-field of machine learning, and deep learning is a sub-field of neural networks.
Machine learning is a branch of artificial intelligence (AI) which refers to a computer's ability to duplicate human cognitive activity. How does it work? Using statistical methods, algorithms are trained to make classifications or predictions, and to uncover key insights in data mining projects. These insights subsequently drive decision making within applications and businesses, ideally impacting key growth metrics. As big data continues to expand and grow, the market demand for data scientists will increase. They will be required to help identify the most relevant business questions and the data to answer them.
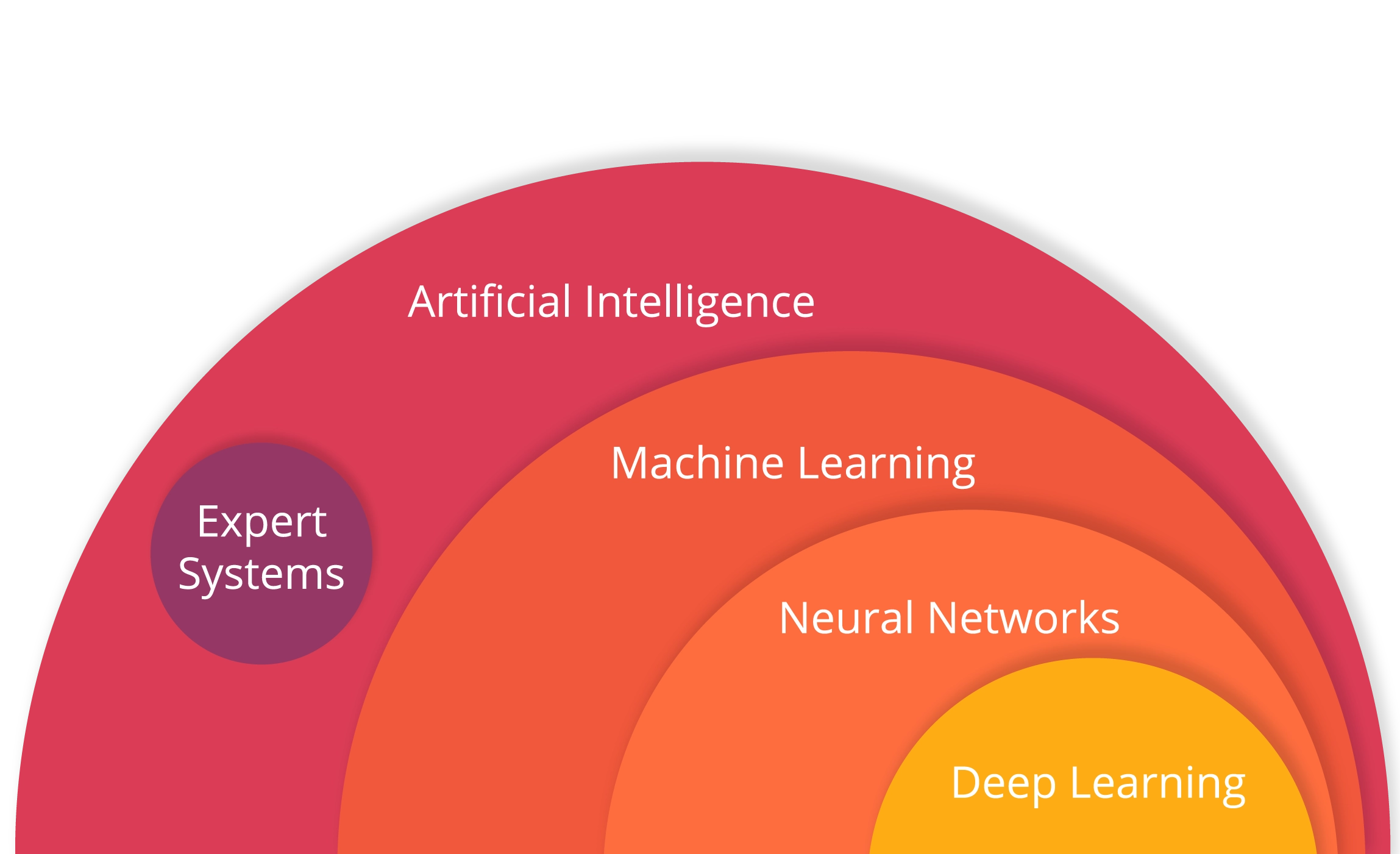
Now, let’s take a closer look at neural networks. Neural networks is a type of computing architecture that is based on a model of how a human brain functions — hence the name "neural." They are composed of node layers, containing an input layer, one or more hidden layers, and an output layer. Each node, or artificial neuron, connects to another and has an associated weight and threshold. If the output of any individual node is above the specified threshold value, that node is activated, sending data to the next layer of the network. Otherwise, no data is passed along to the next layer of the network by that node.
The “deep” in deep learning is just referring to the number of layers in a neural network. A neural network that consists of more than three layers - which would be inclusive of the input and the output - can be considered a deep learning algorithm or a deep neural network. A neural network that only has three layers is just a basic neural network.
Neural networks make many types of artificial intelligence (AI) possible. Large language models (LLMs) such as ChatGPT, AI image generators like DALL-E and predictive AI models all rely to some extent on neural networks.
So, we've gone over the fundamental concepts, and now you've got a grasp of what is included in such a broad term as artificial intelligence. But, taking a trip down memory lane, you'll discover that Ispirer has been involved in artificial intelligence for the past 24 years.
Now, you might be wondering where the evidence is. The thing is, a lot of people tend to overlook all parts of artificial intelligence, for example – the expert system (ES). Read in more details in the next section.
Expert Systems
In the early 80s, an independent direction was formed in research on artificial intelligence, called “expert systems”. It refers to a computer program that uses artificial intelligence (AI) technologies to simulate the judgment and behavior of a human or an organization that has expertise and experience in a particular field. Expert systems were among the first truly successful forms of artificial intelligence (AI) software.
Regardless of the fact that expert systems were created more than 30 years ago, they still retain their relevance due to a number of advantages in comparison with modern systems.

Expert systems consist of three components:
- Knowledge base. This is a knowledge base that is constantly extended with additional information and rules by experts in a particular domain or subject. To make this happen, a knowledge acquisition process is implemented that organizes and structures domain knowledge so that it is ready to be used by the inference engine. The size and quality of the knowledge base influences the precision of the Expert system.
- Inference engine. This is part of the system that uses knowledge from the knowledge base to solve the client's problem. In fact, this “engine” works according to multiple, sometimes initially unrelated, “if-then” rules and combines information from the knowledge base with the rules and finally makes decisions based on the query entered by the user.
- User interface. The part of the system in which the customer interacts to obtain an answer or solve a problem.
Advantages of expert systems will be described further in the article.
Large Language Models
Large Language Models (LLMs) are deep learning algorithms that can recognize, summarize, translate, predict, and generate content using very large datasets. The base of such a model is a transformer. Not a robotic human from the movie, but a set of neural networks that consist of coders and decoders. They extract meanings from the text and understand relationships between words in it.
Transformers are capable of unsupervised training which means they can learn themselves. Because of this self-learning feature they can understand grammar, and learn languages.
With the hype of language models, many developers rushed to use popular models to speed up development. Transforming models are truly excellent assistants, especially in situations where you need to answer a poorly structured question as a human. While a regular computer program will not be able to answer the question “Why did the Beatles song Yesterday become legendary?”, LLM can give a completely detailed and reasoned answer.
At the same time, the information provided by the LLM should only be relied upon with caution. Why? Because it passes on the information with which it has been fed. We are talking here about the LLM ability to hallucinate - the ability of a model to produce fictitious information when it is unable to provide a clear answer to a question.
There are large language models that help developers write code. A great example is GitHub Copilot. It is important to understand what each model can and can’t do. Let's take a look under the hood.
GitHub Copilot runs on advanced machine learning models trained on a large dataset of publicly available code from GitHub repositories. As you start typing code, the AI analyzes the context and provides relevant suggestions in real time.

It uses a language model trained on a vast dataset of public code repositories, which allows it to suggest accurate and relevant code completions in various programming languages. It is said to work great with repetitive code patterns so users can let it generate the rest of the code. The AI assistant can also help you learn a new programming language. The deep learning model behind the data is GPT-4 (as of November 2023) which is easily one of the most impressive AI products ever developed.
In fact, Github Copilot is a double-edged sword. Except for all the pros, it obviously comes with a lot of cons. For example, there is always a risk that developers might become over reliant on Copilot, which can degrade their organic coding skills. And it goes without saying that such tools as Github Copilot or Tabnine provoke some privacy concerns as developers should share their code to work with such instruments.
However, the most popular complaint that developers have about Github Copilot is that most of the time it provides recommendations without taking into account the full code context. This means that it needs to be carefully monitored and tested on everything it offers, which leads to a slowed down development process. In short, everyone should make the decision to use it or not only on an individual basis.
Multilingual Language Models
We’ve reviewed models for coding, now let’s move on to models that can be used for automation of code conversion tasks. The question arises: are there sophisticated models capable of seamlessly converting code from one programming language to another or objects of one database to another? Well, Multilingual Language Models (MLM) can handle this task with the right model training. MLMs are developed to generalize across different linguistic patterns, syntactic structures, and vocabulary found in various languages. Multilingual Language Models are trained on diverse datasets that include text in multiple languages. The training data typically covers a broad range of topics and domains to ensure the model's versatility. The goal is to create models that can effectively work with and provide meaningful insights or outputs for users regardless of the language of the input text.
However, it is worth understanding some of the risks associated with code conversion using MLMs.
Data dependency. MLMs require extensive training data to perform effectively.
Computational Resources. MLMs require significant computational resources to train and run, which might not be feasible for smaller organizations or projects.
Lack of transparency. The decision-making process of MLMs can be opaque, making it difficult to understand how a particular decision was reached.
Model Maintenance. The performance of MLMs can degrade over time if they are not regularly retrained with new data.
Potential for Overfitting. If not properly managed, MLMs can overfit to the training data, reducing their effectiveness on unseen data.
To some extent, ChatGPT can be an example of the Multilingual Language Model, because it has been trained on a diverse range of internet text, which includes content in various languages. Its primary function is to understand and generate human-like text across a variety of languages and domains. And it can be used for conversion to some extent, but you should be clearly aware of all the associated security risks. So far, it is not really formally regulated whether and where the data entered into ChatGPT is stored and how it is processed. Many institutions, corporations, and even entire countries (for example, Italy) restrict access to ChatGPT for a valid reason – the potential for inadvertent data transfer that should remain confidential. Therefore, when using ChatGPT and other tools based on it, you should first check whether the data you provide can be made available to an external company. If not, AI support should be abandoned in this case or the data should be anonymized accordingly so that it does not contain sensitive information and only then should it be used.
Well, then what is the right approach for programming languages conversion or code translation? Expert Systems or MLMs or something else? Let's take a look at them.
Ispirer Toolkit: Expert system with AI at the core
Converting programming language code can be approached in diverse ways. Some companies opt for expert systems, while others recognize the potential of utilizing various language models.
Ispirer Toolkit is a prime example of an expert system. The tool consists of several parts: user interface (GUI, CLI), inference engine and knowledge base. Domain experts have been regularly filling the tool’s knowledge base with conversion rules (for programming languages and database objects) for more than 30 migration directions during the last 24 years. As a result of this consistent work, the tool's knowledge base collected tens of thousands of conversion rules, and approximately one hundred thousand tests were created to ensure the quality of tool results for each nightly release. Ispirer Toolkit was created with the goal to specify the rules in a format that was intuitive and easy to understand, review, and edit by domain experts, so we aimed to make this process as transparent as possible. And we managed, actually.
Now the knowledge base of Ispirer Toolkit includes dozens of supported databases and programming languages. Thanks to the impressive range of supported technologies, Ispirer Toolkit has become a universal solution for any, even the most rare, migration directions. A complete list of supported programming languages and supported databases can be viewed on our website.
Here is how the Ispirer Toolkit core works:

- The client sends a request via the user interface (GUI or CLI) to migrate the source code.
- The request and all the input that the user specified in the user interface enters the rules engine.
- The rules engine via multiple interactions searches and applies the conversion rules that Ispirer experts previously loaded into it.
- The client gets acquainted with the results of the conversion in the final summary and receives the detailed report.
- The client imports the results (objects and/or data) to the target database in case of database migration.
As you can see, the code conversion and database migration processes with Ispirer Toolkit are straightforward. Compared to the often called "black-box" AI based on deep learning, the ES engine follows a set of predefined rules, which makes its behavior predictable and its results reliable. Moreover, the use of Ispirer Toolkit meets the strictest security requirements. The tool works offline, so it does not save or transfer client code to third parties.
Returning to the topic of multilingual models, readers may have a logical question: “What factors contribute to our commitment to the expert system? Why don’t we strive to keep up with the times and turn Ispirer Toolkit into a multilingual model?”. Everything is decided by four main factors:
Security. Ensuring security in model training is paramount, as it entails utilizing extensive datasets that are often only feasible for industry giants. While these large-scale datasets contribute to effective learning, they raise concerns about the confidentiality of clients' code. In fact, all modern language models are “black boxes” as their activity is not transparent. Therefore, we at Ispier want to control the model our solution is based on.
Extensive training data. Data, data and one more time data. Each new training of the model will require hundreds or even thousands of additional source and target code samples. As a company, we do not have access to extensive archives of source code for all supported programming languages and supported databases, as some larger industry players do.
Complexity. One of the most common issues faced by machine learning engineers and data scientists is overfitting. Whenever a machine learning model is trained with a huge amount of data, it starts capturing noise and inaccurate data into the training data set. It negatively affects the performance of a model. It can often be extremely difficult to identify and correct an error, especially when the model is trained on terabytes of data. However, complexity is not only a problem of overfitting. A greater complexity arises when the model needs to produce identical results for almost hundred thousand tests after each retraining.
Equipment. For the model to operate at its optimal speed and capacity, it demands an extensive infrastructure. Picture this: an average language model tips the scales in GBs. Its training requires not just gigabytes, but up to terabytes of code. Achieving swift functionality mandates robust infrastructure and considerable training time.
Having considered the four factors mentioned earlier, readers can reasonably infer that expert systems come with various advantages. What are these benefits? Find out more in the upcoming section.
Expert Systems: the best solution for code conversion?
Here are some of the benefits expert systems provide:
Mature technology. Expert systems are mature and stable technologies that have been tested and improved for years. Ispirer Toolkit is not an exception. Being updated and improved for more than 24 years, it ensures error-free conversion results. As a matter of fact, Ispirer domain experts include new rules to the core of the toolkit every day and bring them to production every single night. With this approach to enhancing the product, we eliminate any possibility of conversion errors.
Domain knowledge. Expert system consists of vast domain knowledge that helps to handle complex code conversion and transformation tasks that require deep understanding of source and target technologies.
Predictability. Expert systems follow multiple, sometimes initially unrelated, predefined rules making their behavior predictable and outcomes reliable. Here we are talking about the same transparency that was discussed earlier in our article.
Customizability. Expert systems allow for customization of the knowledge base and implementation of changes to convert specific patterns in the client's source and target code with minimal time and effort. A single configuration rule can sometimes automate a conversion pattern that occurs multiple times in the client's source code.
Interpretability. Expert systems have a clear and transparent decision-making process, allowing developers to easily debug and continuously improve the system.
Handling ambiguity. Expert systems can handle ambiguous situations better than most, using heuristic rules to make decisions where no clear-cut solution is present.
Hardware requirements. The expert system from Ispirer runs locally at your PC, no resources needed to train it.
Bring Ispirer Toolkit to your migration projects
Large Language Models and Multilingual Models tend to be excessively hyped up - all the mass media exploded after they came to the surface. While opting for a solution to code conversion, it is crucial to set priorities.
If the confidentiality of the code is not important to you, but you value compliance with modern trends, then the choice of models is optimal for you. However, if you do not want to be a test subject and your priorities are reliability, predictability and security of the code, then expert systems are your perfect choice. If you choose an expert system, you should be aware that you are choosing a transition that does not involve any surprises, enormous deployment costs or additional problems for your team. Furthermore, for those without an in-house team, Ispirer offers professional services tailored to meet the demands of any task. This ensures a seamless and dependable integration of expert systems into your workflow, mitigating potential hurdles and ensuring a robust and secure coding environment.