Data Migration Between Databases: a Guide for Real-World Projects
Summary: A smooth and successful data migration project needs your attention to details, some initial work, and a clear strategy.


Data migration between databases can be underestimated at the planning stage. It is usually described in simple terms: extract the data from the source system, load it into the target, and validate the result. On paper, this looks like a well-defined technical task. In reality, it is one of those processes where complexity grows as soon as work begins.
The main reason is that data is never just data. It is the result of years of system evolution, business decisions, shortcuts, fixes, and sometimes undocumented logic. When organizations decide to migrate data between databases, they are not only moving records. They are moving the history and structure of how their business operates.
This is why successful data migration requires a different mindset. It is not about speed or tooling alone. It is about understanding what is being moved, how it behaves, and how to keep it consistent in a new system.
Understanding what you are really migrating
Every migration project starts with seemingly simple questions: how to migrate data from one database to another and what data needs to be moved?
At first, the answer appears obvious — everything. But this assumption rarely holds under closer inspection. Over time, most systems accumulate data that is no longer actively used. Some of it exists for historical reasons, some was created as part of temporary solutions, and some has simply become irrelevant.
Migrating all available data between 2 data sources without evaluation often leads to unnecessary complications in the target system. It increases storage requirements, affects performance, and introduces noise that makes future maintenance more difficult.
A more effective approach is to analyze the data from a functional perspective. In practice, specialists usually separate data into a few categories:
- Data required for day-to-day operations
- Data needed for reporting, analytics, or compliance
- Historical data that can be archived instead of migrated
This step often requires collaboration between technical professionals and business stakeholders, because only business users can confirm whether certain data still has value.
This stage sets the foundation for everything that follows. If the scope is not clearly defined, the migration process becomes unpredictable.
Data rarely fits the new system as expected
Once the scope is established, the next challenge becomes apparent. Data from the source system rarely matches the structure of the target system perfectly.
Even when both databases are built on similar technologies, differences in implementation are inevitable. Data types may not align. Constraints may be stricter in the new system. Some fields may have been redesigned, while others may no longer exist.
For example, it is not uncommon to find dates stored as text in legacy systems, especially if they were initially designed without strict validation rules. When transferring data between storage systems into a modern one, those values must be converted into proper date formats. This may sound trivial until edge cases appear: invalid dates, inconsistent formats, or missing values.
In other cases, a single field in the source system may contain information that needs to be split into multiple attributes in the target. A “full name” field, for instance, might need to be divided into first name and last name. This introduces ambiguity, because not all values follow a consistent pattern.
These examples illustrate a broader point:
“Data migration between different databases is not just about transfer. It is about transformation.”
Ispirer experience: migration from Microsoft SQL Server to PostgreSQL Database on AWS
In our recent project for a leading online fashion retailer, we addressed several PostgreSQL-specific challenges to ensure functional parity and performance:
- Preserve case-insensitive behaviour in string comparisons. Since PostgreSQL is case-sensitive by default, multiple strategies were applied depending on the query context, including citext, ICU collations, and explicit normalization via LOWER(). This is essential for providing users with all possible results and avoiding capitalization mismatches when you migrate data from one database to another (PostgreSQL).
- Migrated XML and JSON, along with hierarchical structures, using PostgreSQL's native json, jsonb, and XML capabilities. Thus, we maintain stable data processing and analytics performance.

The importance of mapping and transformation logic
At the center of any migration process is mapping. This is where each element of the source data is matched to its destination, and rules are defined for how it should be transformed.
Mapping is not just a technical artifact. It is a shared understanding of how data moves from one system to another. It answers questions such as how fields correspond, how values are interpreted, and how inconsistencies are handled.
In many projects, mapping reveals gaps in knowledge about the source system. Typical issues include:
- Fields with unclear or undocumented meaning
- Values that are used inconsistently across records
- Logic that exists in application code but not in the database
Addressing these issues is essential, because unclear mapping leads to incorrect results.
A well-defined mapping process also makes migration repeatable. This is important for testing, as migrations are rarely executed only once. They are run multiple times, refined, and validated before the final execution.
Data quality challenges and their impact
One of the most consistent findings across migration projects is that data quality is rarely perfect. Issues that were tolerated in the original system become visible during migration.
Duplicate records are a common example. In many systems, duplicates exist because validation rules were not enforced at the time of data entry. These duplicates may not cause immediate problems, but they can lead to inconsistencies in reporting and analytics.
Missing values are another frequent issue. Fields that were expected to be optional in the source system may become required in the target. This forces developers to decide how to handle incomplete data.
Inconsistent formats also create challenges. Dates, phone numbers, addresses, and identifiers may follow different formats depending on how they were entered. Standardizing this data is often necessary to ensure compatibility with the target system.
Addressing data quality issues can be done in different ways. Some experts choose to clean the data before migration, while others apply transformation rules during the process. In many cases, a combination of both approaches is used.
What matters is that data quality is treated as a core part of the migration, not as a secondary concern.
Handling edge cases and exceptions
No matter how carefully a migration is planned, there will always be data that does not fit the expected patterns. Records may violate constraints in the target system. Values may exceed allowed limits. Relationships between records may be incomplete or incorrect.
Ignoring these cases is not an option. At the same time, allowing them to block the entire migration can make the process impractical.
A balanced approach is required. Typically, developers agree on a consistent handling strategy, for example:
- Logging problematic records with full context
- Continuing migration for valid data
- Reviewing and resolving issues after the main transfer
However, this approach only works if there is a clear process for reviewing and resolving these exceptions. Otherwise, they accumulate and create inconsistencies in the target system.
Need an expert view on your data migration project?
Validation beyond basic checks
Validation is often underestimated, especially in early stages of migration planning. It is tempting to rely on simple checks, such as comparing the number of records before and after migration.
While these checks are necessary, they are far from sufficient. Data can match in volume and still be incorrect in structure or meaning.
More advanced validation involves comparing aggregated values, such as totals, counts, or averages. For example, the total value of all transactions should remain consistent before and after migration. If it does not, this indicates a problem that needs to be investigated.
Equally important is validating relationships between entities. Foreign keys, references, and dependencies must be preserved. If these relationships are broken, the system may behave unpredictably.
In practice, effective validation usually combines several approaches:
- Record-level comparison for critical entities
- Aggregate checks for financial or analytical data
- Business-level validation through reports and real use cases
Ultimately, validation should also include business-level checks. Reports should produce the same results. Users should be able to find and use data as expected. These checks provide confidence that the migration has been successful from a functional perspective.
Migration strategies and system availability
Another important aspect of data migration between different databases is how it affects system availability.
In some cases, systems can be taken offline during migration. This simplifies the process, as data can be transferred in a single step without concern for ongoing changes.
However, in many modern environments, downtime is not acceptable. Systems must remain operational, even during migration. This requires a different approach.
Incremental migration is commonly used in such scenarios. The bulk of the data is transferred first, followed by continuous synchronization of changes. This ensures that the target system stays up to date while the source system remains active.
The final step, often referred to as cutover, involves switching from the source system to the target. This step must be carefully coordinated to ensure that no data is lost and that users experience minimal disruption.
Managing this process manually can be complex, especially when dealing with large volumes of data and high transaction rates.
The role of specialized tools in data migration
As migration projects grow in scale and complexity, relying solely on custom scripts and manual processes becomes increasingly difficult. This is where specialized data migration tools provide significant value.
One example is Ispirer Data Migrator, an enterprise-grade solution designed to streamline data migration while minimizing operational risks.
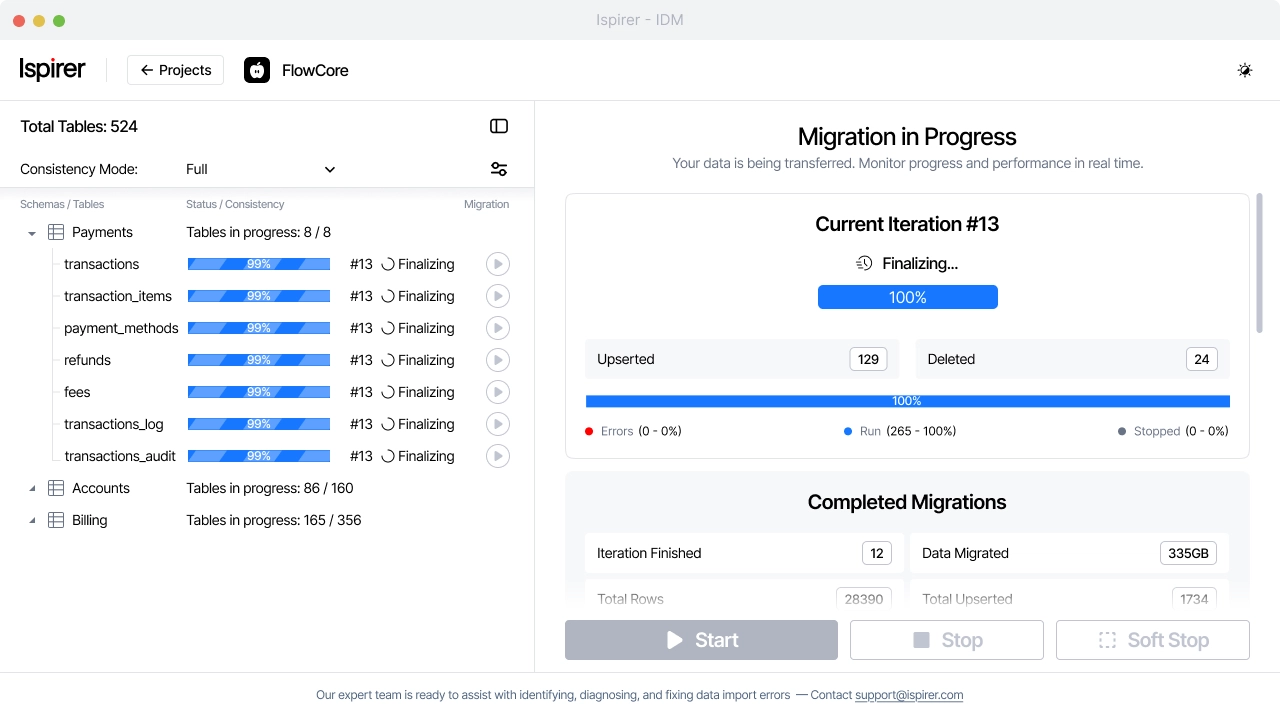
Ispirer Data Migrator combines high-speed data transfer with capabilities such as Change Data Capture, which keeps the source and target systems synchronized while migration is in progress.
This is especially useful in environments where downtime must be kept to a minimum. Instead of stopping the system, data can be migrated while it continues to run, and the final switch happens when both sides are already aligned.
Another practical advantage is the ability to work with the source database in read-only mode. This reduces the risk of unintended changes and ensures that the source system remains stable throughout the process.
The solution also supports custom mapping and data transformation, which is essential for handling complex migration scenarios. Instead of forcing data into a predefined structure, it allows teams to define transformation rules that match their specific requirements.
Performance is handled through parallel processing and optimized data transfer mechanisms, including support for binary data. This helps reduce migration time and avoid bottlenecks.
Reliability is also built into the process. If something interrupts the migration, it can continue from the same point without losing data. At the same time, monitoring tools provide visibility into progress and system load, so teams can react quickly if needed.
The overall approach is structured and iterative. Data is migrated in stages, progress is monitored, and synchronization continues until the difference between systems is minimal. At that point, the transition to the new system can be completed with minimal impact on operations.
I want to try Ispirer Data Migrator
Testing when you migrate data from one database to another
Testing is where all aspects of migration come together. No matter how well the process is designed, real-world data always introduces unexpected challenges.
Test runs allow teams to validate transformation logic, measure performance, and identify issues that were not visible during planning. They also provide an opportunity to refine mapping rules and improve data quality.
Multiple test iterations are typically required. Each run reveals new insights and helps reduce uncertainty. By the time the final migration is executed, the process should be well understood and predictable.
Defining success in data migration
It is easy to measure technical aspects of migration, such as execution time or the number of records processed. However, these metrics do not define success.
A successful migration is one where the business can continue to operate without disruption.
In many cases, the most successful migrations are the ones that go unnoticed. There are no incidents, no urgent fixes, and no need for post-migration corrections.
“Achieving this outcome requires attention to detail at every stage of the process and a collaboration between technical teams and business stakeholders. Also, it often involves the use of tools that provide the necessary level of control and reliability.”
Table Of Content
- Understanding what you are really migrating
- Data rarely fits the new system as expected
- The importance of mapping and transformation logic
- Data quality challenges and their impact
- Handling edge cases and exceptions
- Validation beyond basic checks
- Migration strategies and system availability
- The role of specialized tools in data migration
- Testing when you migrate data from one database to another
- Defining success in data migration
Do you have a migration project ahead?
Talk to expert. Save your time